It's Always DNS
There’s a joke among sysadmins: it’s always DNS. DNS is an integral part of the modern internet. It often works and therefore nobody ever thinks about it. But when it doesn’t work, weird things happen — and nobody ever thinks about DNS. Even when they know it’s always DNS. Recently I had my own “it’s always DNS” moment, and I figured I’d share my experience here so that maybe you’ll remember: it’s always DNS.
After migrating from Cacti to Prometheus, I noticed that I was often missing data in Grafana. Sometimes I’d even get an alert that scraping an SNMP host had failed. This would happen somewhat randomly, and I couldn’t figure out what was causing it. I tweaked a bunch of things including timeouts, and even compiled my own fork of snmp_exporter to leverage exponential retry logic in go-snmp. My efforts here proved futile, as ultimately the issue was DNS. Tweaking the retry logic had no effect as it only applies once the “connection” is established. I had missed this important bit, as more careful analysis of the error would have identified that my troubles were due to DNS.

I kept being misled by the snmp-exporter logs. Sometimes there would be legitimate timeouts, that looked like this:
ts=2022-11-30T20:39:59.291Z caller=collector.go:282 level=info module=openbsd target=brooklyn.matthoran.com msg="Error scraping target" err="error getting target brooklyn.matthoran.com: request timeout (after 3 retries)"
However, these errors would be momentary and subsequent requests would succeed. More concerning were longer outages. Those errors looked like this:
ts=2022-11-25T12:44:44.197Z caller=collector.go:282 level=info module=openbsd target=brooklyn.matthoran.com msg="Error scraping target" err="error connecting to target brooklyn.matthoran.com: error establishing connection to host: dial udp: lookup brooklyn.matthoran.com: i/o timeout"
This i/o timeout misled me, and if I’d read the error more careful, I’d have noticed: it was DNS.
SNMP is a UDP based protocol. That means that a “dial” in Go parlance is simply a DNS lookup. In fact, that’s right there in the error message: lookup. There’s no three-way handshake with UDP, but I kept thinking something was going wrong with the connection between GKE and my home router (brooklyn.)
Since the issue was so sporadic, I figured that UDP was just living up to its name: the Unreliable Datagram Protocol. My graphs were good enough and I figured I’d just live with the missing data. However, I was still scratching my head due to another issue. The recent blog posts I’d written were not being indexed by Google. While I kept submitting these posts for indexing (and have a sitemap.xml), the search console unhelpfully indicated that these pages were “Discovered - currently not indexed”. Great. What does that mean?!
Searching Google for help with itself was of little use. But if I’d looked a bit closer at some of the suggestions, I would have realized: it was DNS. The confusing thing was that I could load up the URL in the search console and all looked good. But Google would just never index the page. Ultimately the issue was that my DNS was so flaky that by the time Google would get around to indexing, there would be a temporary name resolution failure.
The search console does have an incredibly useful crawl stats tool. However, given that the DNS failures were sporadic, crawl stats didn’t show any issues with blog.matthoran.com. Again, I suspect that the sporadic nature of the failures would mean that the indexer would put my blog posts back into the queue, check that DNS was okay, start to crawl, fail to resolve, repeat. Unfortuantely even now the crawl stats page for blog.matthoran.com indicates no issues, but as you can see, once my DNS issues were fixed on November 26 there was a huge spike in crawl requests.
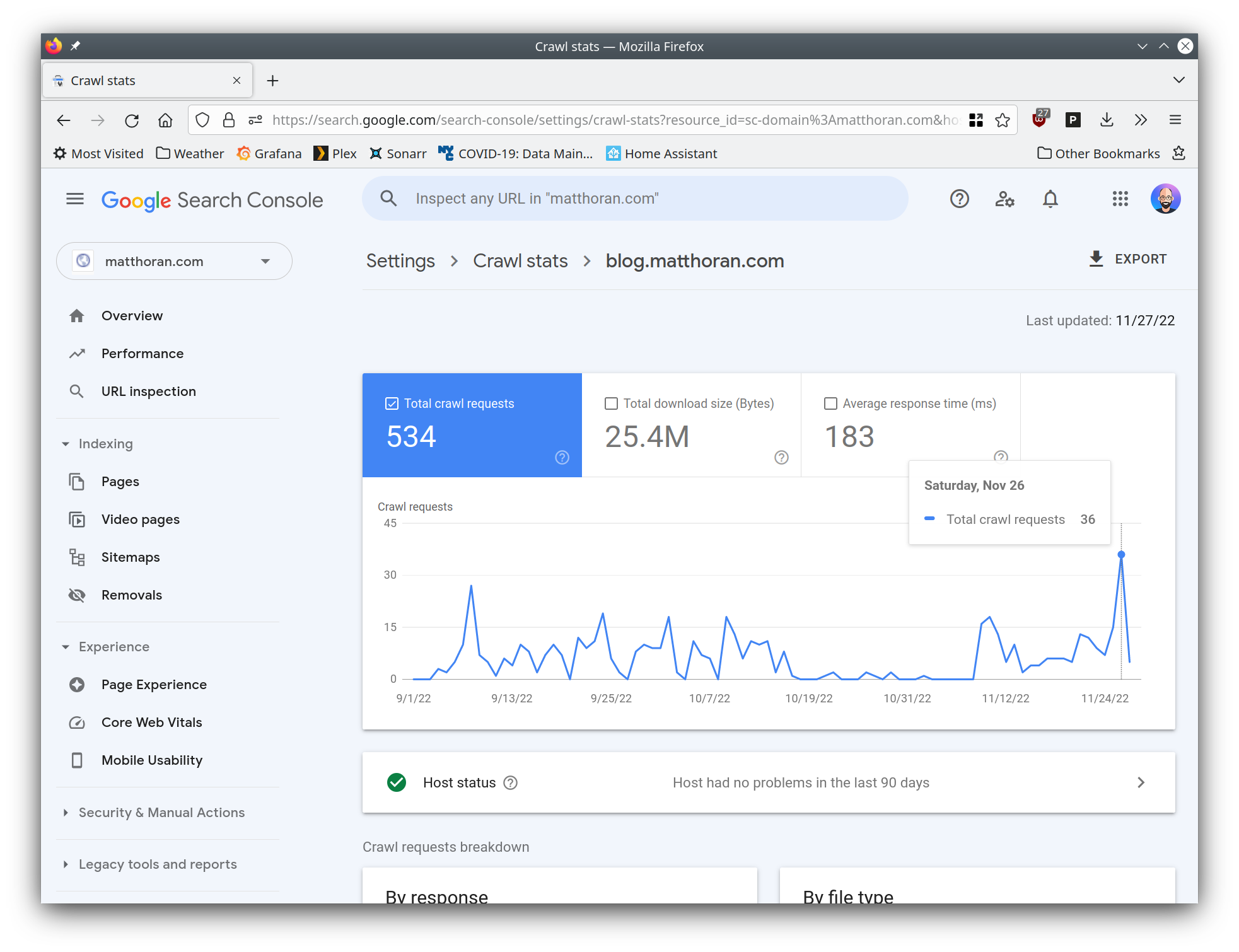
Last Wednesday I finally realized what was going on. The sporadic DNS failures became far less sporadic. I was seeing DNS failures myself if I tried to resolve matthoran.com or any of its subdomains. I was seeing requests directly to my uptream nameservers time out as well. My blackbox monitoring indicated this as well — but I had written them off due to the unreliable nature of UDP. However, I was starting to get pages from Grafana, meaning that DNS was failing to resolve for 15 minutes or more. I finally realized that something was up.
To test my assumption I configured Kubernetes node local DNS cache to resolve matthoran.com directly from my primary nameserver1. This confirmed my suspicion: it was DNS. My blackbox alerts immediately resolved, and the SNMP exporter was no longer timing out. However, this wasn’t a great solution, as anyone not using my primary DNS server would still get timeouts. I still had to fix my DNS.
I decided to go with ClouDNS as a secondary DNS provider. Within a few minutes my records were live on ClouDNS. I went to my registrar and updated my nameservers. Then I removed the node local DNS cache configuration and saw that everything was working as expected. Another great option would have been NS1, which offers a free developer account with up to 50 DNS records and 500k queries a month. However, I was worried about this query limit and have just shy of 50 records. ClouDNS pricing is a bit more attractive for a domain of my size, though NS1 tools and features (e.g. TSIG) are supperior. However, I was told that TSIG will be added to CloudDNS, and their service otherwise works great.
Given my DNS was now working reliably, I decided on a hunch to re-submit all my recent blog posts to Google for indexing. I went to bed and was delighted to find that my recent posts had all been indexed! Yet another reminder that it’s always DNS.
-
This worked well. However, GKE only allows configuration of CoreDNS through the kube-dns ConfigMap. This results in CoreDNS being configured with a forward entry to the upstream nameserver. If the returned record cannot be fully resolved by that upstream nameserver without recursion (read: you are trying to resolve a CNAME that cannot be resolved by that nameserver), then resolution will fail. Perhaps a more appropriate configuration for stub domains would be to use the secondary plugin, allowing transfer of records from a primary. Alternatively, if GKE allowed configuration of the CoreDNS
Corefile, I could have bumped up the TTL of cached records as a workaround. Regardless, be aware of the limitations of the CoreDNSforwardplugin. ↩︎